Stage
Time- and energy-efficient embedded AI for Tensor Processing Units
Date de publication
11.11.25
Prise de poste souhaitée
02.02.26
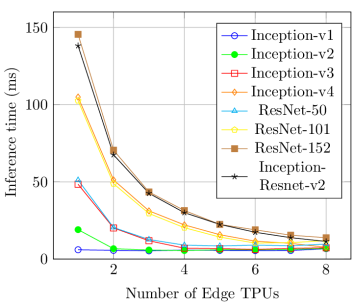
Context. Tensor Processing Units (TPUs) [2, 3] are application-specific integrated circuits designed specifically for accelerating core machine learning operations like matrix multiplications and convolutions. TPUs are increasingly applied in embedded applications thanks to their low energy consumption and significant acceleration of neural net inference (https://coral.ai/docs/edgetpu/benchmarks). They can accelerate the inference time by up to 30x compared with embedded CPUs and deliver high performance per watt at a very small footprint. Our preliminary benchmarks [5, 6] on an ASUS AI Accelerator CRL-G18U-P3D1, with 8 Google Edge TPUs, show that pipeline depth (the number of TPUs used) has a very significant impact on inference times for large and medium-sized networks (see the figure on the left). Running large models on an Edge TPU requires fetching the remaining part of the model parameters from main memory, incurring a high memory transaction latency. With pipelining, a model can be divided into multiple smaller segments using the Edge TPU Compiler, and each segment can run on a different TPU fitting its internal memory. Finally, our tests show that reloading the neural network models stored on a TPU incurs a high context switch overhead (from 9 to 15 ms).
This internship. Our study will investigate the factors that contribute to the real-time performance and power consumption of deep neural networks executed on multiple Tensor Processing Units (TPUs) in low-powered and time-sensitive embedded systems. Its aim is to identify the interplay between three key aspects: inference time, power consumption, and accuracy. We will undertake the following steps:
- Testbed for multi-TPU power consumption measurement. The instantaneous power consumption of different neural networks running on a multi-TPU board ASUS CRL-G18U-P3DF can be measured using the current sensors. A microcontroller (e.g., Arduino Uno or STM32) can collect the measurements in real-time from the current sensors (e.g., ACS712 series) connected to the TPU board PCI interface and send them to the host computer. Several frameworks can be implemented with the firmware already available (e.g., PowerSensor2, https://gitlab.com/astron-misc/PowerSensor/).
- Neural Network Pruning for TPU. Various software optimization methods [1, 4], such as pruning, quantization, or weight sharing, can reduce deep neural networks’ computational requirements and memory footprint. By applying these optimization techniques and measuring power consumption during execution on multi-TPUs, a trade-off between power savings and performance degradation in terms of time and accuracy can be established. This part of the project will be undertaken in collaboration with Laboratoire d’InfoRmatique en Image et Systèmes d’information (LIRIS-CNRS) in Lyon.
- Edge TPU topology search. In multi-TPU pipelining, a set of Tensor Processing Units is reserved for pipelined execution. Each TPU processes a stage of the model and passes intermediate results to the next TPU. Typically, the TPUs are connected in a linear pipeline. However, other topologies are possible. Since long pipelines may be inefficient for certain neural network models, running more but shorter pipelines can be a better option in such cases. This part of the project will be carried out in collaboration with the Technical University of Munich (TUM).

- Benchmarking suite for TPUs. The final step is to create scripts to automate the tests of compressed neural networks with different segmentations and with different numbers of TPUs being used, and interpret the benchmarking results (consumption energy, inference time, precision).
Research group. The project is a collaboration among the Laboratory for Analysis and Architecture of Systems (LAAS-CNRS), the Laboratory for Computer Science in Images and Information Systems (LIRIS-CNRS), and the Technical University of Munich (TUM). The host laboratory is the LAAS-CNRS in Toulouse, France. The internship will be co-supervised by Dr. Tomasz Kloda (LAAS-CNRS), Dr. Stefan Duffner (LIRIS-CNRS), and Binqi Sun (TUM).
Contact. For inquiries about the position, please contact Dr. Tomasz Kloda (tomasz.kloda@laas.fr).
Qualifications. A graduate student of electrical engineering or computer engineering or similar. Good C and Python programming skills, knowledge of Linux and embedded systems as well as basic knowledge of machine learning.
Duration. 6 months. The ideal starting period is January/March 2026 with some flexibility.
Salary. 650 euros / month
References.
[1] Anthony Berthelier, Thierry Chateau, Stefan Duffner, Christophe Garcia, and Christophe Blanc. Deep model compression and architecture optimization for embedded systems: A survey. Journal of Signal Processing Systems, 93:863 – 878, 2020.
[2] John L. Hennessy and David A. Patterson. A new golden age for computer architecture. Commun. ACM, 62(2):48–60, jan 2019.
[3] Norman P. Jouppi, Cliff Young, Nishant Patil, and David Patterson. A domain-specific architecture for deep neural networks. Commun. ACM, 61(9):50–59, aug 2018.
[4] Tailin Liang, John Glossner, Lei Wang, Shaobo Shi, and Xiaotong Zhang. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing, 461:370–403, 2021.
[5] Binqi Sun, Tomasz Kloda, Jiyang Chen, Cen Lu, and Marco Caccamo. Schedulability analysis of non-preemptive sporadic gang tasks on hardware accelerators. In 2023 IEEE 29th Real-Time and Embedded Technology and Applications Symposium (RTAS), pages 147–160, 2023.
[6] Binqi Sun, Tomasz Kloda, Chu-ge Wu, and Marco Caccamo. Partitioned scheduling and parallelism assignment for real-time DNN inference tasks on multi-TPU. In Proceedings of the 61st ACM/IEEE Design Automation Conference, DAC ’24, New York, NY, USA, 2024. Association for Computing Machinery.